Artificial Intelligence is a vital part of human activities. Researchers have made significant progress in this field, leading to innovative technologies. Now, machines can understand human language, which is changing how we live and work.
This development, known as Natural Language Processing, is a big step forward in Machine Learning.
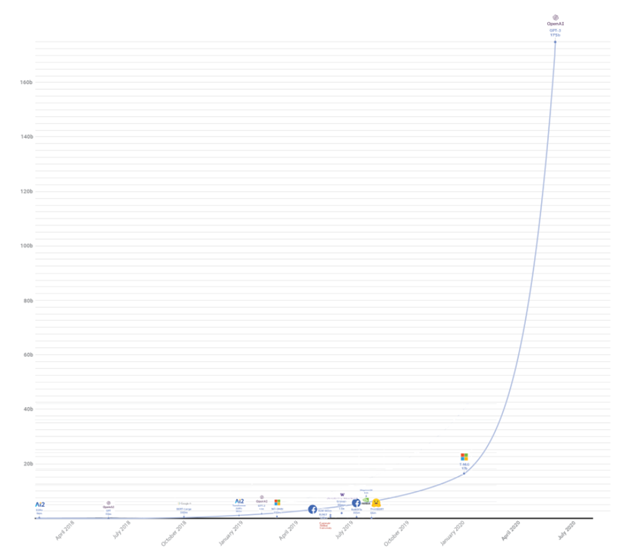
In 2020, OpenAI, an organization focused on safe artificial intelligence, introduced GPT-3, the latest natural language processing technology. GPT-3 is a highly intelligent system that learns from vast amounts of digital text to create new and creative content. It can mimic human writing remarkably well and is praised for its fluency. However, its capabilities are considered too risky for public release. GPT-3 is part of a series of language tools developed by OpenAI, following GPT-1 and GPT-2. These models have revolutionized natural language processing, enabling quick and accurate responses with minimal or no examples. This article explores the development and evolution of GPT models.
As suggested in the name, GPT-3 is the third in a series of NLP tools designed by OpenAI. Before its launch, the model has taken years of development and has its journey to reach the state of innovation as we know it today within the field of AI text generation. This article will discuss the journey and evolution of GPT models i.e.: GPT-1, GPT-2, and GPT-3.
Before GPT, NLP models were heavily trained on large amounts of annotated data for a particular task. This caused a major limitation as the amount of labeled data needed to train the model accurately was not easily available. The NLP models were limited to what they have been trained for and failed to perform out-of-the-box tasks. To overcome these limitations OpenAI proposed a Generative Language Model (GPT-1) built using unlabeled data and then allowing users to fine-tune the language model so that it can perform downstream tasks such as classification, question answering, sentiment analysis, etc. This means that the model takes input (a sentence/a question) and tries to generate an appropriate response, and the data used for training the model is not labeled.
In 2018, OpenAI introduced GPT-1, a generative language model trained on a vast BooksCorpus dataset. This model excelled at understanding extensive text passages and complex relationships within the text. GPT-1 utilized a 12-layer decoder from the transformer architecture, incorporating self-attention mechanisms for training. One of its key achievements was its ability to perform tasks without specific training (zero-shot performance), showcasing the effectiveness of its pre-training approach. By building on transfer learning, GPT-1 became a valuable tool for various natural language processing tasks, requiring minimal adjustments. Its success paved the way for other models to explore generative pre-training with larger datasets and more parameters, further enhancing its capabilities.
GPT uses the Decoder part of the Transformer Model (Source: Attention is all you need)
Later in 2019, OpenAI developed a Generative pre-trained Transformer 2 (GPT-2) using a larger dataset and adding additional parameters to build a stronger language model. Similar to GPT-1, GPT-2 leverages the decoder of the transformer model. Some of the significant developments in GPT-2 is its model architecture and implementation, with 1.5 billion parameters it became 10 times larger than GPT-1 (117 million parameters), also it has 10 times more parameters and 10 times the data compared to its predecessor GPT-1. It is trained upon a diverse dataset making it powerful in terms of solving various language tasks related to translation, summarization, etc. by just using the raw text as input and taking few or no examples of training data. GPT-2 evaluation upon several datasets of downstream tasks, showed that it outperformed by improving the accuracy significantly in identifying long-range dependencies and predicting sentences.
GPT uses the Decoder part of the Transformer Model (Source: Attention is all you need)
GPT-3 is the third version of the Generative pre-training Model series so far. It is a massive language prediction and generation model developed by OpenAI capable of generating long sequences of the original text. GPT-3 became the OpenAI’s breakthrough AI language program. In simple words, it is a software application that can automatically generate paragraphs so unique that it almost sounds as if a person wrote them. GPT-3 program is currently available with restricted access through an API on the cloud, and access is needed to explore the tool. It has created some intriguing applications since its launch. Its significant benefit is its size, it contains about 175 billion parameters and is 100 times larger than GPT-2. It is trained upon a 500-billion-word data set (known as “Common Crawl”) collected from the vast internet and content repository. Its other significant and surprising ability is to perform simple arithmetic problems, including writing code snippets and execute intelligent tasks. The results are faster response time and accuracy allowing NLP models to benefit business by effectively and consistently maintaining best practices and reducing human errors. Many researchers and developers have described it as the ultimate black box AI approach due to its complexity and enormous size. This makes it a lot expensive and inconvenient to perform inference, also its billion-parameter size makes it heavy on resources and a challenge for practical applicability on tasks in its current form. It is currently available as an API through an application process interface provided by OpenAI.
The purpose of GPT-3 was to make language processing more powerful and faster than its previous versions and without any special tuning. Most of the previous language processing models (such as BERT) require in-depth fine-tuning with thousands of examples to teach the model how to perform downstream tasks. With GPT-3 users can eliminate the fine-tuning step. The difference between the three GPT models is their size. The original Transformer Model had around 110 million parameters. GPT-1 adopted the size and with GPT-2 the number of parameters was enhanced to 1.5 billion. With GPT-3, the number of parameters was boosted to 175 billion, making it the largest neural network.
GPT-1
GPT-2
GPT-3
Parameters
117 Million
1.5 Billion
175 Billion
Decoder Layers
12
48
96
Context Token Size
512
1024
2048
Hidden Layer
768
1600
12288
Batch Size
64
512
3.2M
FGPT uses the Decoder part of the Transformer Model (Source: Attention is all you need)
GPT language models are a gigantic neural network with a great potential for automating tasks. Since NLP is an active area of research, it comes with its limitations that include repetitive text, misunderstanding of contextual phrases or technical restrictions, etc.
Understanding and processing language is complicated. It involves extensive training to grasp not just words but also their meanings, how sentences are structured, and how to provide meaningful and contextually appropriate responses. GPT-3 stands out because it can generate new and creative text in response to any input. Its abilities are incredibly useful in tasks like answering questions, assisting customers, searching for information, generating reports, creating content, and even writing code.
Their capabilities can amplify human efforts in a wide range of tasks from question and answers, customer service, document searches, report generation, content or code generation, and many more, making it an AI tool with great potential. With businesses and researchers focusing their efforts to create value with AI language technology, it will be interesting to see what the next discovery can produce.


.png)
.png)







Leave a Reply