
How to Build Natural Language Processing(NLP) Applications- Detailed Guide

How to Build Natural Language Processing(NLP) Applications
How to Build Natural Language Processing(NLP) Applications- Detailed Guide
How to Build NLP Applications
Building NLP applications
In this Blog, I’m going to show you how NLP applications are typically developed and structured. Although details may vary on a case-by-case basis, understanding the typical process helps you plan and budget before you start developing an application. It also goes a long way if you know best practices in developing NLP applications beforehand.
Real "AI Buzz" | AI Updates | Blogs | Education
Development of NLP applications
The development of NLP applications is a highly iterative process, consisting of many phases of research, development, and operations. Most learning materials such as books and online tutorials focus mainly on the training phase, although all the other phases of application development are equally important for real-world NLP applications. In this section, I briefly introduce what each stage involves. Note that no clear boundary exists between these phases. It is not uncommon that application developers (researchers, engineers, managers, and other stakeholders) go back and forth between some of these phases through trial and error.
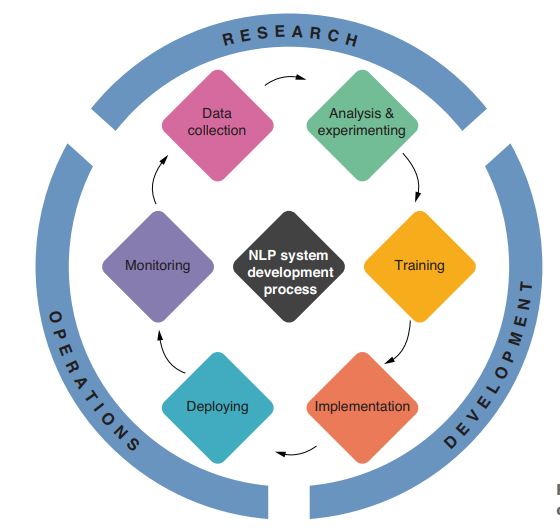
DATA COLLECTION
Most modern NLP applications are based on machine learning. Machine learning, by definition, requires data on which NLP models are trained (remember the definition of ML we talked about previously—it’s about improving algorithms through data). In this phase, NLP application developers discuss how to formulate the application as an NLP/ML problem and what kind of data should be collected. Data can be collected from humans (e.g., by hiring in-house annotators and having them go through a bunch of text instances), crowdsourcing (e.g., using platforms such as Amazon Mechanical Turk), or automated mechanisms (e.g., from application logs or clickstreams).
ANALYSIS AND EXPERIMENTING
After collecting the data, you move on to the next phase where you analyze and run some experiments. For analyses, you usually look for signals such as: What are the characteristics of the text instances? How are the training labels distributed? Can you come up with signals that are correlated with the training labels? Can you come up with some simple rules that can predict the training labels with reasonable accuracy? Should we even use ML? This list goes on and on. This analysis phase includes aspects of data science, where various statistical techniques may come in handy. You run experiments to try a number of prototypes quickly.
The goal in this phase is to narrow down the possible set of approaches to a couple of promising ones, before you go all-in and start training a gigantic model. By running experiments, you wish to answer questions including: What types of NLP tasks and approaches are appropriate for this NLP application? Is this a classification, parsing, sequence labeling, regression, text generation, or some other problem? What is the performance of the baseline approach? What is the performance of the rule-based approach? Should we even use ML? What is the estimate of training and serving time for the promising approaches?
The point of this research phase is to prevent you from wasting your effort writing production code that turns out to be useless at a later stage.
TRAINING
In NLP development, clarity in approach precedes data and resource addition, especially GPUs. Training modern NLP models may take weeks. Gradually increase data and model size to avoid wasted efforts and bugs. Maintain reproducibility for future runs with different hyperparameters.
IMPLEMENTATION
When you have a model that is working with acceptable performance, you move on to the implementation phase. This is when you start making your application “production ready.” This process basically follows software engineering best practices, including: writing unit and integration tests for your NLP modules, refactoring your code, having your code reviewed by other developers, improving the performance of your NLP modules, and dockerizing your application.
DEPLOYING
Your NLP application is finally ready to deploy. You can deploy your NLP application in many ways—it can be an online service, a recurring batch job, an offline application, or an offline one-off task. If this is an online service that needs to serve its predictions in real time, it is a good idea to make this a microservice to make it loosely coupled with other services. In any case, it is a good practice to use continuous integration (CI) for your application, where you run tests and verify that your code and model are working as intended every time you make changes to your application.
MONITORING
In NLP application development, monitoring is vital. It involves checking server performance and ML stats like input and predicted label distributions. Monitoring ensures the model behaves as intended, detecting out-of-domain issues. If discrepancies arise, collecting more in-domain data and repeating the process might be necessary.
Structure of NLP applications
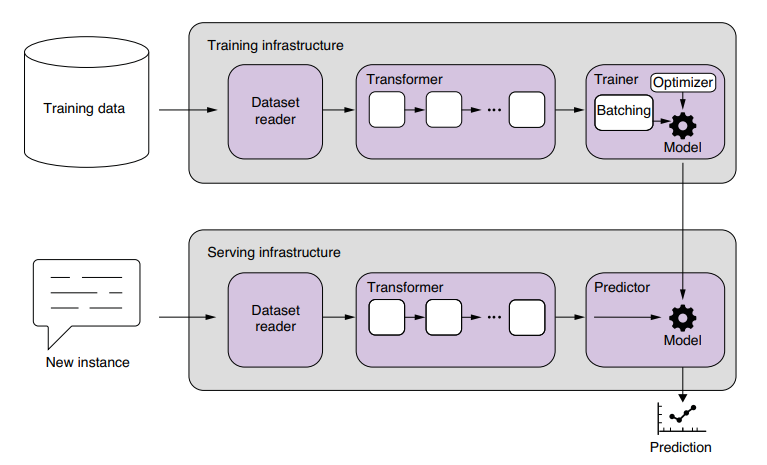
The structures of modern, machine learning–based NLP applications are becoming surprisingly similar for two main reasons—one is that most modern NLP applications rely on machine learning to some degree, and they should follow best practices for machine learning applications. The other is that, due to the advent of neural network models, a number of NLP tasks, including text classification, machine translation, dialog systems, and speech recognition, can now be trained end-to-end, as I mentioned before. Some of these tasks used to be hairy, enormous monsters with dozens of components with complex plumbing. Now, however, some of these tasks can be solved by less than 1,000 lines of Python code, provided that there’s enough data to train the model end-to-end.
Read More







Leave a Reply