
8 Best Data Science and Machine Learning Platforms

8 Best Data Science and Machine Learning Platforms
8 Best Data Science and Machine Learning Platforms
8 Best Data Science and ML Platforms
Real "AI Buzz" | AI Updates | Blogs | Education
1. Neptune

Neptune is a lightweight experiment management tool that helps you keep track of your machine learning experiments and manage all your model metadata. It is very flexible, works with many other frameworks, and thanks to its stable user interface, it enables great scalability.
Here’s what Neptune offers to monitor your ML models:
- Fast and beautiful UI with a lot of capabilities to organize runs in groups, save custom dashboard views and share them with the team
- Version, store, organize, and query models, and model development metadata including dataset, code, env config versions, parameters and evaluation metrics, model binaries, description, and other details
- Filter, sort, and group model training runs in a dashboard to better organize your work
- Compare metrics and parameters in a table that automatically finds what changed between runs and what are the anomalies
- Automatically record the code, environment, parameters, model binaries, and evaluation metrics every time you run an experiment
- Your team can track experiments that are executed in scripts (Python, R, other), notebooks (local, Google Colab, AWS SageMaker) and do that on any infrastructure (cloud, laptop, cluster)
- Extensive experiment tracking and visualization capabilities (resource consumption, scrolling through lists of images)
Neptune is a robust software that lets you store all your data in one place, easily collaborate, and flexibly experiment with your models.
2. Amazon SageMaker
Amazon SageMaker is a platform that enables data scientists to build, train, and deploy machine learning models. It has all the integrated tools for the entire machine learning workflow providing all of the components used for machine learning in a single toolset.
SageMaker is a tool suitable for arranging, coordinating, and managing machine learning models. It has a single, web-based visual interface to perform all ML development steps – notebooks, experiment management, automatic model creation, debugging, and model drift detection
Amazon SageMaker – summary:
- Autopilot automatically inspects raw data, applies feature processors, picks the best set of algorithms, trains and tunes multiple models, tracks their performance, and then ranks the models based on performance – it helps to deploy the best performing model
- SageMaker Ground Truth helps you build and manage highly accurate training datasets quickly
- SageMaker Experiments helps to organize and track iterations to machine learning models by automatically capturing the input parameters, configurations, and results, and storing them as ‘experiments’
- SageMaker Debugger automatically captures real-time metrics during training (such as training and validation, confusion, matrices, and learning gradients) to help improve model accuracy. Debugger can also generate warnings and remediation advice when common training problems are detected
- SageMaker Model Monitor allows developers to detect and remediate concept drift. It automatically detects concept drift in deployed models and gives detailed alerts that help identify the source of the problem
Note
See Neptune’s integration with SageMaker
3. Cnvrg.io

cnvrg is an end-to-end machine learning platform to build and deploy AI models at scale. It helps teams to manage, build and automate machine learning from research to production.
You can run and track experiments in hyperspeed with the freedom to use any compute environment, framework, programming language or tool – no configuration required.
Here are the main features of cnvrg:
- Organize all your data in one place and collaborate with your team
- Real-time visualization allows you to visually track models as they run with automatic charts, graphs and more, and easily share with your team
- Store models and meta-data, including parameters, code version, metrics and artifacts
- Track changes and automatically record code and parameters for reproducibility
- Build production-ready machine learning pipelines in a few clicks with the drag & drop feature
cnvrg lets you store, manage, and easily control all your data, experiments, and flexibly use it to your needs.
4. Iguazio

Iguazio helps in the end-to-end automation of machine learning pipelines. It simplifies development, accelerates performance, facilitates collaboration, and addresses operational challenges.
The platform incorporates the following components:
- A data science workbench that includes Jupyter Notebook, integrated analytics engines, and Python packages
- Model management with experiments tracking and automated pipeline capabilities
- Managed data and machine-learning (ML) services over a scalable Kubernetes cluster
- A real-time serverless functions framework — Nuclio
- Fast and secure data layer that supports SQL, NoSQL, time-series databases, files (simple objects), and streaming
- Integration with third-party data sources such as Amazon S3, HDFS, SQL databases, and streaming or messaging protocols
- Real-time dashboards based on Grafana
Iguazio provides you with a complete data science workflow in a single ready-to-use platform for creating data science applications from research to production.
5. Spell

Spell is a platform for training and deploying machine learning models quickly and easily. It provides a Kubernetes-based infrastructure to run and manage ML experiments, store all your data, and automate the MLOps lifecycle.
Here are some of the main features of Spell:
- Provides base environments for TensorFlow, PyTorch, Fast.ai, and others. Or, you can roll your own.
- You can install any code packages you need using pip, conda, and apt.
- Straightforward and accessible Jupyter workspaces, datasets, and resources
- Runs can be linked together using workflows to manage model training pipelines
- Model metrics automatically generated by Spell
- Hyperparameter search
- Model servers make it easy to productionize models trained on Spell, allowing you to use one tool for both your model training and model serving
6. MLflow

MLflow is an open-source platform that helps manage the whole machine learning lifecycle that includes experimentation, reproducibility, deployment, and a central model registry.
MLflow is suitable for individuals and for teams of any size.
The tool is library-agnostic. You can use it with any machine learning library and in any programming language.
MLflow comprises four main functions:
- MLflow Tracking – an API and UI for logging parameters, code versions, metrics, and artifacts when running machine learning code and for later visualizing and comparing the results
- MLflow Projects – packaging ML code in a reusable, reproducible form to share with other data scientists or transfer to production
- MLflow Models – managing and deploying models from different ML libraries to a variety of model serving and inference platforms
- MLflow Model Registry – a central model store to collaboratively manage the full lifecycle of an MLflow Model, including model versioning, stage transitions, and annotations
Note
See Neptune’s integration with MLflow
7. TensorFlow
Tensorflow is an end-to-end platform for deploying production ML pipelines. It provides a configuration framework and shared libraries to integrate common components needed to define, launch, and monitor your machine learning system.
TensorFlow provides stable Python and C++ APIs, as well as non-guaranteed backward compatible API for other languages. It also supports an ecosystem of powerful add-on libraries and models to experiment with, including Ragged Tensors, TensorFlow Probability, Tensor2Tensor and BERT.
TensorFlow lets you train and deploy your model easily, no matter what language or platform you use – use TensorFlow Extended (TFX) if you need a full production ML pipeline; for running inference on mobile and edge devices, use TensorFlow Lite; train and deploy models in JavaScript environments using TensorFlow.js.
It’s an MLOps tool suitable for beginners and advanced data scientists. It has all the necessary features and gives you the flexibility to use it however you want.
Note
See Neptune’s integration with TensorFlow
8. Kubeflow
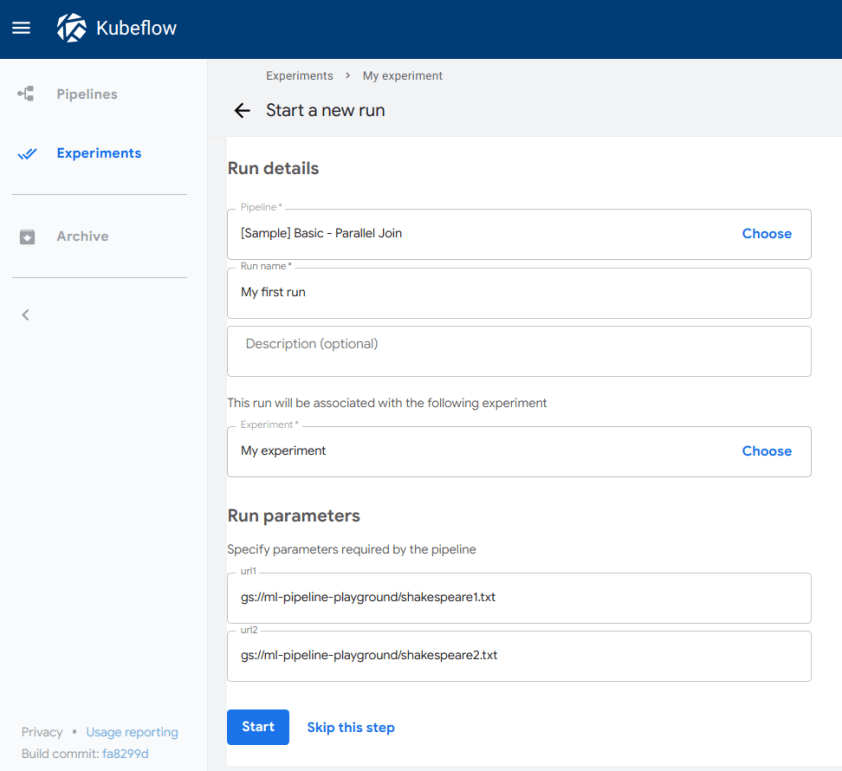
Kubeflow is the ML toolkit for Kubernetes. It helps in maintaining machine learning systems by packaging and managing docker containers.
It facilitates the scaling of machine learning models by making run orchestration and deployments of machine learning workflows easier. It’s an open-source project that contains a curated set of compatible tools and frameworks specific to various ML tasks.
Here’s a short Kubeflow summary:
- A user interface (UI) for managing and tracking experiments, jobs, and runs
- Notebooks for interacting with the system using the SDK
- Re-use components and pipelines to quickly create end-to-end solutions without having to rebuild each time
- Kubeflow Pipelines is available as a core component of Kubeflow or as a standalone installation
- Multi-framework integration
Read More







Leave a Reply